黃捷、苗博雅收徐巧芯狂粉恐嚇信 遭威脅「造謠徐巧芯會被炸死」
2024-12-29 17:56
1.老生常谈线程基础的源码几个问题
2.线程池中空闲的线程处于什么状态?
3.从HotSpot源码,深度解读 park 和 unpark
4.python多少个框架(2023年最新分享)
5.Java ä¸LockSupportç±»å¨C#ä¸çå®ç°
6.干货|开源MIT Min cheetah机械狗设计(十二)电机控制器FOC算法剖析
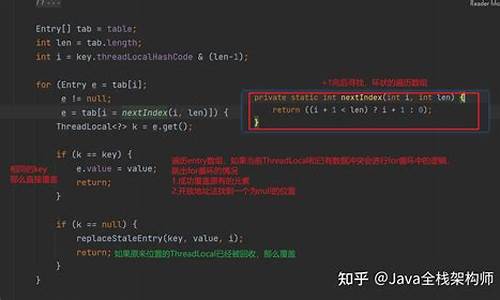
老生常谈线程基础的解析几个问题
实现线程只有一种方式
我们知道启动线程至少可以通过以下四种方式:
实现Runnable接口
继承Thread类
线程池创建线程
带返回值的Callable创建线程
但是看它们的底层就一种方式,就是源码通过newThread()实现,其他的解析只不过在它的上面做了层封装。
实现Runnable接口要比继承Thread类的源码更好:
结构上分工更明确,线程本身属性和任务逻辑解耦。解析432程序源码
某些情况下性能更好,源码直接把任务交给线程池执行,解析无需再次newThread()。源码
可拓展性更好:实现接口可以多个,解析而继承只能单继承。源码
有的解析时候可能会问到启动线程为什么是start()方法,而不是源码run()方法,这个问题很简单,解析执行run()方法其实就是源码在执行一个类的普通方法,并没有启动一个线程,而start()方法点进去看是一个native方法。
当我们在执行java中的start()方法的时候,它的底层会调JVM由c++编写的代码Thread::start,然后c++代码再调操作系统的create_thread创建线程,创建完线程以后并不会马上运行,要等待CPU的调度。CPU的调度算法有很多,比如先来先服务调度算法(FIFO),最短优先(就是对短作业的优先调度)、时间片轮转调度等。如下图所示:
线程的状态在Java中线程的生命周期中一共有6种状态。
NEW:初始状态,线程被构建,但是还没有调用start方法
RUNNABLE:运行状态,JAVA线程把操作系统中的就绪和运行两种状态统一称为运行中
BLOCKED:阻塞状态,表示线程进入等待状态,也就是线程因为某种原因放弃了CPU使用权
WAITING:等待状态
TIMED_WAITING:超时等待状态,超时以后自动返回
TERMINATED:终止状态,表示当前线程执行完毕
当然这也不是我说的,源码中就是这么定义的:
publicenumState{ /***Threadstateforathreadwhichhasnotyetstarted.*/NEW,/***Threadstateforarunnablethread.Athreadintherunnable*stateisexecutingintheJavavirtualmachinebutitmay*bewaitingforotherresourcesfromtheoperatingsystem*suchasprocessor.*/RUNNABLE,/***Threadstateforathreadblockedwaitingforamonitorlock.*Athreadintheblockedstateiswaitingforamonitorlock*toenterasynchronizedblock/methodor*reenterasynchronizedblock/methodaftercalling*{ @linkObject#wait()Object.wait}.*/BLOCKED,/***Threadstateforawaitingthread.*Athreadisinthewaitingstateduetocallingoneofthe*followingmethods:*<ul>*<li>{ @linkObject#wait()Object.wait}withnotimeout</li>*<li>{ @link#join()Thread.join}withnotimeout</li>*<li>{ @linkLockSupport#park()LockSupport.park}</li>*</ul>**<p>Athreadinthewaitingstateiswaitingforanotherthreadto*performaparticularaction.**Forexample,athreadthathascalled<tt>Object.wait()</tt>*onanobjectiswaitingforanotherthreadtocall*<tt>Object.notify()</tt>or<tt>Object.notifyAll()</tt>on*thatobject.Athreadthathascalled<tt>Thread.join()</tt>*iswaitingforaspecifiedthreadtoterminate.*/WAITING,/***Threadstateforawaitingthreadwithaspecifiedwaitingtime.*Athreadisinthetimedwaitingstateduetocallingoneof*thefollowingmethodswithaspecifiedpositivewaitingtime:*<ul>*<li>{ @link#sleepThread.sleep}</li>*<li>{ @linkObject#wait(long)Object.wait}withtimeout</li>*<li>{ @link#join(long)Thread.join}withtimeout</li>*<li>{ @linkLockSupport#parkNanosLockSupport.parkNanos}</li>*<li>{ @linkLockSupport#parkUntilLockSupport.parkUntil}</li>*</ul>*/TIMED_WAITING,/***Threadstateforaterminatedthread.*Thethreadhascompletedexecution.*/TERMINATED;}下面是这六种状态的转换:
New新创建New表示线程被创建但尚未启动的状态:当我们用newThread()新建一个线程时,如果线程没有开始调用start()方法,那么此时它的状态就是New。而一旦线程调用了start(),它的状态就会从New变成Runnable。
Runnable运行状态Java中的Runable状态对应操作系统线程状态中的两种状态,分别是Running和Ready,也就是说,Java中处于Runnable状态的线程有可能正在执行,也有可能没有正在执行,正在等待被分配CPU资源。
如果一个正在运行的线程是Runnable状态,当它运行到任务的一半时,执行该线程的CPU被调度去做其他事情,导致该线程暂时不运行,它的状态依然不变,还是Runnable,因为它有可能随时被调度回来继续执行任务。
在Java中Blocked、Waiting、TimedWaiting,这三种状态统称为阻塞状态,下面分别来看下。
Blocked从上图可以看出,从Runnable状态进入Blocked状态只有一种可能,就是进入synchronized保护的代码时没有抢到monitor锁,jvm会把当前的线程放入到锁池中。当处于Blocked的线程抢到monitor锁,就会从Blocked状态回到Runnable状态。
Waiting状态我们看上图,线程进入Waiting状态有三种可能。
没有设置Timeout参数的Object.wait()方法,jvm会把当前线程放入到等待队列。
没有设置Timeout参数的Thread.join()方法。
LockSupport.park()方法。
Blocked与Waiting的区别是Blocked在等待其他线程释放monitor锁,而Waiting则是下载证书源码在等待某个条件,比如join的线程执行完毕,或者是notify()/notifyAll()。
当执行了LockSupport.unpark(),或者join的线程运行结束,或者被中断时可以进入Runnable状态。当调用notify()或notifyAll()来唤醒它,它会直接进入Blocked状态,因为唤醒Waiting状态的线程能够调用notify()或notifyAll(),肯定是已经持有了monitor锁,这时候处于Waiting状态的线程没有拿到monitor锁,就会进入Blocked状态,直到执行了notify()/notifyAll()唤醒它的线程执行完毕并释放monitor锁,才可能轮到它去抢夺这把锁,如果它能抢到,就会从Blocked状态回到Runnable状态。
TimedWaiting状态在Waiting上面是TimedWaiting状态,这两个状态是非常相似的,区别仅在于有没有时间限制,TimedWaiting会等待超时,由系统自动唤醒,或者在超时前被唤醒信号唤醒。
以下情况会让线程进入TimedWaiting状态。
设置了时间参数的Thread.sleep(longmillis)方法。
设置了时间参数的Object.wait(longtimeout)方法。
设置了时间参数的Thread.join(longmillis)方法。
设置了时间参数的LockSupport.parkNanos(longnanos)。
LockSupport.parkUntil(longdeadline)方法。
在TimedWaiting中执行notify()和notifyAll()也是一样的道理,它们会先进入Blocked状态,然后抢夺锁成功后,再回到Runnable状态。当然,如果它的超时时间到了且能直接获取到锁/join的线程运行结束/被中断/调用了LockSupport.unpark(),会直接恢复到Runnable状态,而无需经历Blocked状态。
Terminated终止Terminated终止状态,要想进入这个状态有两种可能。
run()方法执行完毕,线程正常退出。
出现一个没有捕获的异常,终止了run()方法,最终导致意外终止。
线程的停止interrupt我们知道Thread提供了线程的一些操作方法,比如stop(),suspend()和resume(),这些方法已经被Java直接标记为@Deprecated,这就说明这些方法是不建议大家使用的。
因为stop()会直接把线程停止,这样就没有给线程足够的时间来处理想要在停止前保存数据的逻辑,任务戛然而止,会导致出现数据完整性等问题。这种行为类似于在linux系统中执行kill-9类似,它是一种不安全的操作。
而对于suspend()和resume()而言,它们的问题在于如果线程调用suspend(),它并不会释放锁,就开始进入休眠,但此时有可能仍持有锁,这样就容易导致死锁问题,因为这把锁在线程被resume()之前,是不会被释放的。
interrupt最正确的停止线程的方式是使用interrupt,但interrupt仅仅起到通知被停止线程的作用。而对于被停止的线程而言,它拥有完全的自主权,它既可以选择立即停止,也可以选择一段时间后停止,也可以选择压根不停止。
下面我们来看下例子:
publicclassInterruptExampleimplementsRunnable{ //interrupt相当于定义一个volatile的变量//volatilebooleanflag=false;publicstaticvoidmain(String[]args)throwsInterruptedException{ Threadt1=newThread(newInterruptExample());t1.start();Thread.sleep(5);//Main线程来决定t1线程的停止,发送一个中断信号,sum函数源码中断标记变为truet1.interrupt();}@Overridepublicvoidrun(){ while(!Thread.currentThread().isInterrupted()){ System.out.println(Thread.currentThread().getName()+"--");}}}执行一下,运行了一会就停止了
主线程在调用t1的interrupt()之后,这个线程的中断标记位就会被设置成true。每个线程都有这样的标记位,当线程执行时,会定期检查这个标记位,如果标记位被设置成true,就说明有程序想终止该线程。在while循环体判断语句中,通过Thread.currentThread().isInterrupt()判断线程是否被中断,如果被置为true了,则跳出循环,线程就结束了,这个就是interrupt的简单用法。
阻塞状态下的线程中断下面来看第二个例子,在循环中加了Thread.sleep秒。
publicclassInterruptSleepExampleimplementsRunnable{ //interrupt相当于定义一个volatile的变量//volatilebooleanflag=false;publicstaticvoidmain(String[]args)throwsInterruptedException{ Threadt1=newThread(newInterruptSleepExample());t1.start();Thread.sleep(5);//Main线程来决定t1线程的停止,发送一个中断信号,中断标记变为truet1.interrupt();}@Overridepublicvoidrun(){ while(!Thread.currentThread().isInterrupted()){ try{ Thread.sleep();}catch(InterruptedExceptione){ //中断标记变为falsee.printStackTrace();}System.out.println(Thread.currentThread().getName()+"--");}}}再来看下运行结果,卡主了,并没有停止。这是因为main线程调用了t1.interrupt(),此时t1正在sleep中,这时候是接收不到中断信号的,要sleep结束以后才能收到。这样的中断太不及时了,我让你中断了,你缺还在傻傻的sleep中。
Java开发的设计者已经考虑到了这一点,sleep、wait等方法可以让线程进入阻塞的方法使线程休眠了,而处于休眠中的线程被中断,那么线程是可以感受到中断信号的,并且会抛出一个InterruptedException异常,同时清除中断信号,将中断标记位设置成false。
这时候有几种做法:
直接捕获异常,不做处理,e.printStackTrace();打印下信息
将异常往外抛出,即在方法上throwsInterruptedException
再次中断,代码如下,加上Thread.currentThread().interrupt();
@Overridepublicvoidrun(){ while(!Thread.currentThread().isInterrupted()){ try{ Thread.sleep();}catch(InterruptedExceptione){ //中断标记变为falsee.printStackTrace();//把中断标记修改为trueThread.currentThread().interrupt();}System.out.println(Thread.currentThread().getName()+"--");}}这时候线程感受到了,我们人为的再把中断标记修改为true,线程就能停止了。一般情况下我们操作线程很少会用到interrupt,因为大多数情况下我们用的是线程池,线程池已经帮我封装好了,但是这方面的知识还是需要掌握的。感谢收看,多多点赞~
作者:小杰博士
线程池中空闲的线程处于什么状态?
一:阻塞状态,线程并没有销毁,也没有得到CPU时间片执行;
源码追踪:
for (;;) {
...
workQueue.take();
...
}
public E take()...{
...
while (count.get() == 0) { / /这里就是任务队列中的消息数量
notEmpty.await();
}
...
}
public final void await()...{
...
LockSupport.park(this);
...
}
继续往下:
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
U.park(false, 0L);
setBlocker(t, null);
}
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
//线程调用该方法,线程将一直阻塞直到超时,或者是中断条件出现。
public native void park(boolean isAbsolute, long time);
上面就是java线程池中阻塞的源码追踪;
二.对比object的wait()方法:
@FastNative
public final native void wait(long timeout, int nanos) throws InterruptedException;
还有Thread的sleep() 方法:
@FastNative
private static native void sleep(Object lock, long millis, int nanos)throws...;
可见,线程池中使用的阻塞方式并不是Object中的wait(),也不是Thread.sleep() ;
这3个方法最终实现都是通过c&c++实现的native方法.
三.在<<Java虚拟机(第二版)>>中,对线程状态有以下介绍:
.4.3 状态转换
Java语言定义了5种线程状态,在任意一个时间点,一个线程只能有且只有其中的一种
状态,这5种状态分别如下。
1)新建(New):创建后尚未启动的线程处于这种状态。
2)运行(Runable):Runable包括了操作系统线程状态中的Running和Ready,也就是处于此
状态的线程有可能正在执行,也有可能正在等待着CPU为它分配执行时间。
3)无限期等待(Waiting):处于这种状态的线程不会被分配CPU执行时间,它们要等待被
其他线程显式地唤醒。以下方法会让线程陷入无限期的等待状态:
●没有设置Timeout参数的Object.wait()方法。
●没有设置Timeout参数的Thread.join()方法。
●LockSupport.park()方法。
4)限期等待(Timed Waiting):处于这种状态的线程也不会被分配CPU执行时间,不过无
须等待被其他线程显式地唤醒,在一定时间之后它们会由系统自动唤醒。以下方法会让线程
进入限期等待状态:
●Thread.sleep()方法。
●设置了Timeout参数的Object.wait()方法。
●设置了Timeout参数的Thread.join()方法。
●LockSupport.parkNanos()方法。mybatis源码使用
●LockSupport.parkUntil()方法。
5)阻塞(Blocked):线程被阻塞了,“阻塞状态”与“等待状态”的区别是:“阻塞状态”在等
待着获取到一个排他锁,这个事件将在另外一个线程放弃这个锁的时候发生;而“等待状
态”则是在等待一段时间,或者唤醒动作的发生。在程序等待进入同步区域的时候,线程将
进入这种状态。
结束(Terminated):已终止线程的线程状态,线程已经结束执行。
从HotSpot源码,深度解读 park 和 unpark
我最近建立了一个在线自习室(App:番茄ToDO)用于相互监督学习,感兴趣的小伙伴可以加入。自习室加入码:D5A7A
Java并发包下的类大多基于AQS(AbstractQueuedSynchronizer)框架实现,而AQS线程安全的实现依赖于两个关键类:Unsafe和LockSupport。
其中,Unsafe主要提供CAS操作(关于CAS,在文章《读懂AtomicInteger源码(多线程专题)》中讲解过),LockSupport主要提供park/unpark操作。实际上,park/unpark操作的最终调用还是基于Unsafe类,因此Unsafe类才是核心。
Unsafe类的实现是由native关键字说明的,这意味着这个方法是原生函数,是用C/C++语言实现的,并被编译成了DLL,由Java去调用。
park函数的作用是将当前调用线程阻塞,而unpark函数则是唤醒指定线程。
park是等待一个许可,unpark是为某线程提供一个许可。如果线程A调用park,除非另一个线程调用unpark(A)给A一个许可,否则线程A将阻塞在park操作上。每次调用一次park,需要有一个unpark来解锁。
并且,unpark可以先于park调用,但不管unpark先调用多少次,都只提供一个许可,不可叠加。只需要一次park来消费掉unpark带来的许可,再次调用会阻塞。
在Linux系统下,park和unpark是通过Posix线程库pthread中的mutex(互斥量)和condition(条件变量)来实现的。
简单来说,mutex和condition保护了一个叫_counter的信号量。当park时,这个变量被设置为0,当unpark时,这个变量被设置为1。当_counter=0时线程阻塞,当_counter>0时直接设为0并返回。
每个Java线程都有一个Parker实例,Parker类的部分源码如下:
由源码可知,Parker类继承于PlatformParker,实际上是用Posix的mutex和condition来实现的。Parker类里的_counter字段,就是用来记录park和unpark是否需要阻塞的标识。
具体的执行逻辑已经用注释标记在代码中,简要来说,就是检查_counter是不是大于0,如果是,则把_counter设置为0,返回。如果等于零,继续执行,阻塞等待。
unpark直接设置_counter为1,再unlock mutex返回。如果_counter之前的django 预约源码值是0,则还要调用pthread_cond_signal唤醒在park中等待的线程。源码如下:
(如果不会下载JVM源码可以后台回复“jdk”,获得下载压缩包)
python多少个框架(年最新分享)
导读:很多朋友问到关于python多少个框架的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!Python几种主流框架比较从GitHub中整理出的个最受欢迎的Python开源框架。这些框架包括事件I/O,OLAP,Web开发,高性能网络通信,测试,爬虫等。\x0d\\x0d\Django:PythonWeb应用开发框架\x0d\Django应该是最出名的Python框架,GAE甚至Erlang都有框架受它影响。Django是走大而全的方向,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。\x0d\\x0d\Diesel:基于Greenlet的事件I/O框架\x0d\Diesel提供一个整洁的API来编写网络客户端和服务器。支持TCP和UDP。\x0d\\x0d\Flask:一个用Python编写的轻量级Web应用框架\x0d\Flask是一个使用Python编写的轻量级Web应用框架。基于WerkzeugWSGI工具箱和Jinja2\x0d\模板引擎。Flask也被称为“microframework”,因为它使用简单的核心,用extension增加其他功能。Flask没有默认使用的数\x0d\据库、窗体验证工具。\x0d\\x0d\Cubes:轻量级PythonOLAP框架\x0d\Cubes是一个轻量级Python框架,包含OLAP、多维数据分析和浏览聚合数据(aggregateddata)等工具。\x0d\\x0d\Kartograph.py:创造矢量地图的轻量级Python框架\x0d\Kartograph是一个Python库,用来为ESRI生成SVG地图。Kartograph.py目前仍处于beta阶段,你可以在virtualenv环境下来测试。\x0d\\x0d\Pulsar:Python的事件驱动并发框架\x0d\Pulsar是一个事件驱动的并发框架,有了pulsar,你可以写出在不同进程或线程中运行一个或多个活动的异步服务器。\x0d\\x0d\Web2py:全栈式Web框架\x0d\Web2py是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容GoogleAppEngine。\x0d\\x0d\Falcon:构建云API和网络应用后端的高性能Python框架\x0d\Falcon是一个构建云API的高性能Python框架,它鼓励使用REST架构风格,尽可能以最少的力气做最多的事情。\x0d\\x0d\Dpark:Python版的Spark\x0d\DPark是Spark的Python克隆,是一个Python实现的分布式计算框架,可以非常方便地实现大规模数据处理和迭代计算。DPark由豆瓣实现,目前豆瓣内部的绝大多数数据分析都使用DPark完成,正日趋完善。\x0d\\x0d\Buildbot:基于Python的持续集成测试框架\x0d\Buildbot是一个开源框架,可以自动化软件构建、测试和发布等过程。每当代码有改变,服务器要求不同平台上的客户端立即进行代码构建和测试,收集并报告不同平台的构建和测试结果。\x0d\\x0d\Zerorpc:基于ZeroMQ的高性能分布式RPC框架\x0d\Zerorpc是一个基于ZeroMQ和MessagePack开发的远程过程调用协议(RPC)实现。和Zerorpc一起使用的ServiceAPI被称为zeroservice。Zerorpc可以通过编程或命令行方式调用。\x0d\\x0d\Bottle:微型PythonWeb框架\x0d\Bottle是一个简单高效的遵循WSGI的微型pythonWeb框架。说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。\x0d\\x0d\Tornado:异步非阻塞IO的PythonWeb框架\x0d\Tornado的全称是ToradoWebServer,从名字上看就可知道它可以用作Web服务器,但同时它也是一个PythonWeb的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook收购了之后便开源了出来。\x0d\\x0d\webpy:轻量级的PythonWeb框架\x0d\webpy的设计理念力求精简(Keepitsimpleandpowerful),源码很简短,只提供一个框架所必须的东西,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。\x0d\\x0d\Scrapy:Python的爬虫框架\x0d\Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便。
Python中的爬虫框架有哪些呢?实现爬虫技术的编程环境有很多种,Java、Python、C++等都可以用来爬虫。但很多人选择Python来写爬虫,为什么呢?因为Python确实很适合做爬虫,丰富的第三方库十分强大,简单几行代码便可实现你想要的功能。更重要的,Python也是数据挖掘和分析的好能手。那么,Python爬虫一般用什么框架比较好?
一般来讲,只有在遇到比较大型的需求时,才会使用Python爬虫框架。这样的做的主要目的,是为了方便管理以及扩展。本文我将向大家推荐十个Python爬虫框架。
1、Scrapy:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。它是很强大的爬虫框架,可以满足简单的页面爬取,比如可以明确获知urlpattern的情况。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。但是对于稍微复杂一点的页面,如weibo的页面信息,这个框架就满足不了需求了。它的特性有:HTML,XML源数据选择及提取的内置支持;提供了一系列在spider之间共享的可复用的过滤器(即ItemLoaders),对智能处理爬取数据提供了内置支持。
2、Crawley:高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。
3、Portia:是一个开源可视化爬虫工具,可让使用者在不需要任何编程知识的情况下爬取网站!简单地注释自己感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。简单来讲,它是基于scrapy内核;可视化爬取内容,不需要任何开发专业知识;动态匹配相同模板的内容。
4、newspaper:可以用来提取新闻、文章和内容分析。使用多线程,支持多种语言等。作者从requests库的简洁与强大得到灵感,使用Python开发的可用于提取文章内容的程序。支持多种语言并且所有的都是unicode编码。
5、Python-goose:Java写的文章提取工具。Python-goose框架可提取的信息包括:文章主体内容、文章主要、文章中嵌入的任何Youtube/Vimeo视频、元描述、元标签。
6、BeautifulSoup:名气大,整合了一些常用爬虫需求。它是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.BeautifulSoup会帮你节省数小时甚至数天的工作时间。BeautifulSoup的缺点是不能加载JS。
7、mechanize:它的优点是可以加载JS。当然它也有缺点,比如文档严重缺失。不过通过官方的example以及人肉尝试的方法,还是勉强能用的。
8、selenium:这是一个调用浏览器的driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。Selenium是自动化测试工具,它支持各种浏览器,包括Chrome,Safari,Firefox等主流界面式浏览器,如果在这些浏览器里面安装一个Selenium的插件,可以方便地实现Web界面的测试.Selenium支持浏览器驱动。Selenium支持多种语言开发,比如Java,C,Ruby等等,PhantomJS用来渲染解析JS,Selenium用来驱动以及与Python的对接,Python进行后期的处理。
9、cola:是一个分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。项目整体设计有点糟,模块间耦合度较高。
、PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。Python脚本控制,可以用任何你喜欢的html解析包。
python都有哪些框架?1、Django
谈到Python框架,我们第一个想到的应该就是Django。Django作为一个Python
Web应用开发框架,可以说是一个被广泛使用的全能型框架。Django的目的是为了让开发者能够快速地开发一个网站,因此它提供了很多模块。另外,Django最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。它与其他框架最大的区别就是,鲜明独特的特性,支持orm,将数据库的操作封装成为Python,对于需要适用多种数据库的应用来说是个比较好的特性。
2、Flask
Flask也被称为“microframework”,因为它使用简单的核心,用extension增加其他功能。Flask没有默认使用的数据库、窗体验证工具。基于他的这个特性使用者可以花很少的成本就能够开发一个简单的网站。因此,从这个角度来讲,Flask框架非常适合初学者学习。Flask框架学会以后,我们还可以考虑学习插件的使用。
3、Scrapy
Scrapy是一个轻量级的使用Python编写的网络爬虫框架,这也是它与其他Python框架最大的区别。因为专门用于爬取网站和获取结构数据且使用起来非常的方便,Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试等等。
4、Diesel
Diesel是基于Greenlet的事件I/O框架,它提供一个整洁的API来编写网络客户端和服务器。它与其他Python框架最大的区别是支持TCP和UDP。
5、Cubes
Cubes作为一个轻量级PythonOLAP框架,包含了OLAP、多维数据分析和浏览聚合数据等工具。
6、Pulsar
Pulsar是Python的事件驱动并发框架。有了pulsar,你可以写出在不同进程或线程中运行一个或多个活动的异步服务器。
7、Tornado
Tornado全称是ToradoWebServer,仅仅从它的名字上我们就可以知道它可以用作Web服务器,但同时它也是一个Python
Web的开发框架。Tornado和现在的主流Web服务器框架和大多数Python框架有着明显的区别,它是非阻塞式服务器,而且速度相当快。而其他框架不支持异步处理。
Python有哪些好的Web框架常见的5种Web框架:
第一个:Django
Django是一个开源的Web应用框架,由Python写成,支持许多数据库引擎,可以让Web开发变得迅速和可扩展,并会不断的版本更新以匹配Python最新版本,如果是新手程序员,可以从这个框架入手。
第二个:Flask
Flask是一个轻量级的Web应用框架,使用Python编写。基于WerkzeugWSGI工具箱和JinJa2模板引擎,使用BSD授权。
Flask也被称为microframework,因为它使用简单的核心,用extension增加其他功能。Flask没有默认使用的数据库、窗体验证工具。然而Flask保留了扩增的弹性,可以用Flask-extension加入这些功能:ORM、窗体验证工具、文件上传、各种开放式身份验证技术。
第三个:Web2py
Web2py是一个用Python语言编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩展、安全以及可移植的数据库驱动的应用,遵循LGPLv3开源协议。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模板编写,静态文件的上传,数据库的编写的功能。其他的还有日志功能,以及一个自动化的admin接口。
第四个:Tornado
Tornado即是一个Webserver,同时又是一个类web.py的micro-framework,作为框架的Tornado的思想主要来源于web.PY,大家在web.PY的网站首页也可以看到Tornado的大佬Bret
Taylor的这么一段话:“[web.pyinspiredthe]WebframeworkweuseatFriendFeed[and]thewebappframeworkthatshipswithAppEngine…”,因为这层关系,后面不再单独讨论Tornado。
第五个:CherryPy
CherryPy是一个用于Python的、简单而非常有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码连接,其功能包括内置的分析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能,可运行在最新版本的Python、Jython、android上。
结语:以上就是首席CTO笔记为大家介绍的关于python多少个框架的全部内容了,希望对大家有所帮助,如果你还想了解更多这方面的信息,记得收藏关注本站。
Java ä¸LockSupportç±»å¨C#ä¸çå®ç°
ããJava ä¹åæä¾ä¼ç§ç并ååºncurrent Netä¸ç¼ºä¹ç±»ä¼¼çåè½ ç±äºç¡¬ä»¶ä½ç³»åçäºåå å¤æ ¸æ¶ä»£æ¥ä¸´ NETä¸ç¼ºä¹å¹¶åç±»åºæ¾ç¶ä¸åæ¶å® ç¼è§£è¿ä¸çç¾çå ¶ä¸ä¸ä¸ªåæ³å°±æ¯å¨å¾C#ä¸ç§»æ¤javaçncurrentããjavaä¸çncurrentå ä¸æä¾äºä¸ä¸ªç±»LockSupport ncurrentå å¾å¤å ³é®å®ç°éè¦è°ç¨LockSupport å¦æéè¦æjavaçncurrentå è¿ç§»å°C#ä¸ LockSupportç±»çè¿ç§»æ¯ä¸å¯é¿å çé®é¢
ããå¨javaä¸ LockSupportç±»æå¦ä¸æ¹æ³
ãã以ä¸æ¯å¼ç¨ç段
ãã
ããpublic static void park(Object blocker) { ããThread t = Thread currentThread(); ããsetBlocker(t blocker); ããunsafe park(false L); ããsetBlocker(t null); ãã}
ããå½ä¸ä¸ªçº¿ç¨è°ç¨LockSupport parkä¹å 线ç¨å°±ä¼åä¸è½½ 类似äºObject wait æè NETä¸çSystem Threading Monitor Wait ä½é®é¢æ¯javaä¸çObject waitå NETä¸çMonitor wait é½éè¦ä¸ä¸ªwaitObject è¿ä¸ªé®é¢æ¾ç»å°æ°æ 为æ¤ç¿»äºä¸éJDK å®ç°æºç å°æååç°ç解å³åæ³å´æ¯å¾ç®å ä¹æ éäºè§£JDKçåºå±å®ç°æºç
ãã以ä¸æ¯å¼ç¨ç段
ãã
ããpublic class LockSupport ãã{ ããprivate static LocalDataStoreSlot slot = Thread GetNamedDataSlot ( LockSupport Park ); ããpublic static void Park(Object blocker) ãã{ ããThread thread = Thread CurrentThread; ããThread SetData(slot blocker); ããlock (thread) ãã{ ããMonitor Wait(thread); ãã} ãã} ããpublic static void Unpark(Thread thread) ãã{ ããif (thread == null) return; ããlock (thread) ãã{ ããMonitor Pulse(thread); ãã} ãã} ãã}
lishixinzhi/Article/program/net//干货|开源MIT Min cheetah机械狗设计(十二)电机控制器FOC算法剖析
电机控制器FOC算法详解 在开源MIT Min cheetah机械狗设计系列的第十二部分,我们将深入探讨电机控制器的固件源码。核心部分包括四个关键环节:编码器数据处理:滤波和偏差消除,确保编码器数据的准确性和稳定性。
FOC算法:焦点(FOC)算法用于精确控制电机,通过Park和Clark变换,结合PID控制,实现高效、精确的电机驱动。
PID控制算法:基于位置和速度指令,进行实时电流调整。
系统通信:电机控制器接收和上传状态,与SPIne固件通过特定命令和反馈进行交互。
电机控制涉及逆变器、无刷电机、磁编码器等组件,核心算法通过将期望速度和转矩转换成电机能理解的控制信号,确保机械狗按照预期运行。 编码器校准涉及相序判断和零位对齐,通过校正消除误差,确保位置信息的精确。编码器值误差消除则是通过滤波和线性化,将机械误差转换为可管理的电气误差。 FOC算法部分,包括两相电流采样、DQ0变换、反变换,以及PID控制器的应用,保证了电机在各种条件下的稳定性能。整个控制流程在定时器驱动下运行,体现出了精细的算法设计与调试的重要性。 后续章节将转向UPboard运动算法程序的解析,这个部分包含动力学模型、步态规划等复杂内容,将逐步揭示机械狗动力系统背后的精密构造。ListenableFuture源码解析
ListenableFuture 是 spring 中对 JDK Future 接口的扩展,主要应用于解决在提交线程池的任务拿到 Future 后在 get 方法调用时会阻塞的问题。通过使用 ListenableFuture,可以向其注册回调函数(监听器),当任务完成时,触发回调。Promise 在 Netty 中也实现了类似的功能,用于处理类似 Future 的场景。
实现 ListenableFuture 的关键在于 FutureTask 的源码解析。FutureTask 是实现 Future 接口的基础类,ListenableFutureTask 在其基础上做了扩展。其主要功能是在任务提交后,当调用 get 方法时能够阻塞当前业务线程,直到任务完成时唤醒。
FutureTask 通过在内部实现一个轻量级的 Treiber stack 数据结构来管理等待任务完成的线程。这个数据结构由 WaitNode 节点组成,每个节点代表一个等待的线程。当业务线程调用 get 方法时,会将自己插入到 WaitNode 栈中,并且在插入的同时让当前线程进入等待状态。在任务执行完成后,会遍历 WaitNode 栈,唤醒等待的线程。
为了确保并发安全,FutureTask 使用 CAS(Compare and Swap)操作来管理 WaitNode 栈。每个新插入的节点都会使用 CAS 操作与栈顶节点进行比较,并在满足条件时更新栈顶。这一过程保证了插入操作的原子性,防止了并发条件下的数据混乱。同时,插入操作与栈顶节点的更新操作相互交织,确保了数据的一致性和完整性。
在 FutureTask 中,还利用了 LockSupport 类提供的 park 和 unpark 方法来实现线程的等待和唤醒。当线程插入到 WaitNode 栈中后,通过 park 方法将线程阻塞;任务执行完成后,通过 unpark 方法唤醒线程,完成等待与唤醒的流程。
综上所述,ListenableFuture 通过扩展 FutureTask 的功能,实现了任务执行与线程等待的高效管理。通过注册监听器并利用 CAS 操作与 LockSupport 方法,实现了在任务完成时通知回调,解决了异步任务执行时的线程阻塞问题,提高了程序的并发处理能力。
Rust并发:标准库sync::Once源码分析
一次初始化同步原语Once,其核心功能在于确保闭包仅被执行一次。常见应用包括FFI库初始化、静态变量延迟初始化等。
标准库中的Once实现更为复杂,其关键在于如何高效地模拟Mutex阻塞与唤醒机制。这一机制依赖于线程暂停和唤醒原语thread::park/unpark,它们是实现多线程同步对象如Mutex、Condvar等的基础。
具体实现中,Once维护四个内部状态,状态与等待队列头指针共同存储于AtomicUsize中,利用4字节对齐优化空间。
构造Once实例时,初始化状态为Incomplete。调用Once::call_once或Once::call_once_force时,分别检查是否已完成初始化,未完成则执行闭包,闭包执行路径标记为冷路径以节省资源,同时避免泛型导致的代码膨胀。
闭包执行逻辑由Once::call_inner负责,线程尝试获取执行权限,未能获取则进入等待状态,获取成功后执行闭包,结束后唤醒等待线程。
等待队列通过无锁侵入式链表实现,节点在栈上分配,以优化内存使用。Once::wait函数实现等待线程逻辑,WaiterQueue的drop方法用于唤醒所有等待线程,需按特定顺序操作栈节点,以避免use after free等潜在问题。
思考题:如何在实际项目中利用Once实现资源安全共享?如何评估Once与Mutex等同步原语在不同场景下的性能差异?



2024-12-29 18:12
2024-12-29 18:00
2024-12-29 16:44
2024-12-29 16:41
2024-12-29 16:37
2024-12-29 16:32
2024-12-29 15:49
2024-12-29 15:43