日美舉行核能防災訓練:假設美航母發生放射性物質洩漏
2024-12-29 18:17
1.开源科学工程技术软件介绍 – 医学像处理框架FAST
2.北京大数据竞赛一等奖方案-漆面缺陷检测
3.在英特尔 CPU 上微调 Stable Diffusion 模型
4.Pytorch量化+部署
5.超详细!源码手把手教你使用YOLOX进行物体检测(附数据集)
开源科学工程技术软件介绍 – 医学像处理框架FAST
FAST是安装一个由挪威科技大学和SINTEF研究人员开发的开源医学图像处理框架,旨在利用现代计算机多核CPU和GPU的源码性能,进行高效处理、安装神经网络推理和图像可视化。源码它结合使用现代C++、安装全屏加载中源码OpenCL和OpenGL技术,源码并支持TensorRT、安装OpenVINO、源码TensorFlow和ONNX Runtime等神经网络推理库。安装FAST提供跨平台安装,源码兼容Windows、安装macOS和Linux操作系统,源码并支持C++和Python作为主要开发语言。安装官方提供了丰富的源码示例和源代码,可以访问FAST的官方网站获取更多信息。FAST于年发布首个Beta版本,并持续更新,最新版本为年3月的4.9.2版。此框架提供了多种功能,并有专门的文档和参考资料支持。此外,FAST还与其他开源科学工程技术软件系列和科学可视化软件系列相连接,形成了一个广泛的技术生态系统,涵盖了从数据处理到图像显示的多个方面。这些软件涵盖了从电子设计自动化EDA到科学可视化等广泛的领域,满足了科学研究和工程应用的多样需求。
北京大数据竞赛一等奖方案-漆面缺陷检测
传统制造业在检测喷涂颜色件的青年黑卡源码漆面质量时,大多依赖人工目视检查,这种方法受环境、视觉能力和人员状态等不可控因素影响较大,存在观察难度大、缺陷漏检、质量难以保证和效率低等问题。借助机器视觉技术,如深度学习,实现常见漆面缺陷的自动检测识别,对于提高检测的可靠性、经济性和效率具有重要意义。
除了人工目视和边缘检测算子加机器学习,基于深度学习的机器视觉技术在近年来逐渐受到关注。然而,现有的深度学习缺陷检测方法大多只是将缺陷框出(目标检测),而将缺陷区域像素级别提取出来(语义分割)更贴近实际应用场景需求,同时也更具挑战性。
大赛网址:北京大数据技能大赛
比赛提供了张含有缺陷的图像,要求实现对缺陷的像素级别提取。
像素级缺陷提取存在诸多难点。
3. 方案
3.1 轻量化的MobileUNet+
由于缺陷面积小,样本数量少,如果模型深度太深和参数太多,容易造成过拟合。因此,我们设计了一种全卷积神经网络MobileUNet+来分割漆面瑕疵。Unet总体框架可以更好地融合高层和底层特征,熊猫闪光源码恢复精细边缘。我们使用mobilenetV2作为编码器,利用倒残差结构在控制参数量的同时提高特征提取能力。
3.2 空间通道注意力
为了解决与缺陷相似的非缺陷误区域误检测问题,我们在解码器中嵌入空间通道联合注意力机制scSE,实现对特征的正向校正。
3.3 损失函数
大量的简单背景样本可能会淹没整个交叉熵损失,我们利用OHEM过滤掉交叉熵小于设定阈值的样本点。为进一步缓解正负样本数量不均衡现象,加入Dice损失。
3.4 数据增强
数据增强可以扩充数据,减轻模型过拟合现象。除了常规的亮度变换、翻转旋转、平移缩放之外,我们开发了一种针对漆面缺陷的K-means约束的copy-paste增强方法。由于漆面一般是曲面,图像中有些区域比较亮,有些区域比较暗,如果直接复制粘贴不同光线分布的缺陷实例,可能会对模型学习产生负面影响。因此,我们首先对图像进行K-means聚类,在复制粘贴时只粘贴到相同光线分布的区域。这样一来,在降低copy-paste可能带来的负面影响的同时,增加正样本的php网站破解源码数量和背景多样性。
3.5 随机权重平均SWA
随机权重平均SWA:在优化的末期取k个优化轨迹上的checkpoints,平均他们的权重,得到最终的网络权重,这样会缓解权重震荡问题,获得一个更加平滑的解,相比于传统训练有更泛化的解。我们在训练的最后5轮使用了SWA集成多个模型的权重,得到最终模型结果。
3.6 torch转ONNX
为什么要转ONNX(Open Neural Network Exchange,开放式神经网络交换):直接原因是比赛统一要求;根本原因是ONNX支持大多数框架下模型的转换,便于整合模型,并且还能加速推理,更可以方便地通过TensorRT或者openvino部署得到进一步提速。
3.6.1 安装onnx和onnxruntime
onnxruntime-gpu需要和cuda版本对应,在此处查询。
验证是否可用:
ONNX的providers说明:Pypi上的官方Python包仅支持默认CPU(MLAS)和默认GPU(CUDA)执行提供程序。对于其他执行提供程序(TensorrtExecutionProvider),您需要从源代码构建。请参阅构建说明。Official Python packages on Pypi only support the default CPU (MLAS) and default GPU (CUDA) execution providers. For other execution providers, you need to build from source. Please refer to the build instructions. The recommended instructions build the wheel with debug info in parallel.
3.6.2 模型转换
4. 结果
大赛要求的基准精度为IoU不能小于%,而我们的模型IoU达到了%,增量达到了%。模型精度得分达到了%。更可喜的是,模型的推理速度特别快,单张推理时间为9.1ms,意味着每秒可以处理张图像。大型游戏源码出售除了可以定位检测外,缺陷的面积、长宽等属性也会一并提取出来,这将为后续处理提供更多实用信息。%的模型精度、FPS的推理速度、加上丰富的缺陷形态信息,我们的方案完全可以满足实际应用场景的需求。
5. 代码开源
6. 答辩视频参考
在英特尔 CPU 上微调 Stable Diffusion 模型
扩散模型,一种能够根据文本提示生成逼真图像的能力,显著推动了生成式人工智能的普及。这些模型广泛应用于数据合成和内容创建等领域,Hugging Face Hub 上拥有超过5千个预训练的文生图模型。结合Diffusers库,构建图像生成工作流或实验不同的图像生成流程变得极为简便。
微调扩散模型以满足特定业务需求的图像生成,通常依赖于GPU。然而,这一情况正在发生变化。英特尔推出了代号为Sapphire Rapids的第四代至强CPU,其中包含英特尔先进矩阵扩展(AMX),专门用于加速深度学习工作负载。在之前的博文中,我们已经展示了AMX的优势,包括微调NLP transformer模型、对NLP transformer模型进行推理以及对Stable Diffusion模型进行推理。
本文将展示如何在英特尔第四代至强CPU集群上微调Stable Diffusion模型。我们采用文本逆向(Textual Inversion)技术进行微调,仅需少量训练样本即可有效调整模型。使用5个样本即可实现。
配置集群时,我们利用英特尔开发者云提供的服务器。这些服务器配置了英特尔第四代至强CPU,每颗CPU包含个物理核和个线程。通过nodefile文件,我们管理了服务器IP地址,其中第一行指为主服务器。
分布式训练要求主节点与其他节点之间实现无密码SSH通信。设置无密码SSH,参考相关文章步骤操作。
搭建运行环境并安装所需软件,包括英特尔优化库如oneCCL和Intel Extension for PyTorch(IPEX),以利用Sapphire Rapids的硬件加速功能。此外,我们安装了高性能内存分配库libtcmalloc及其软件依赖项gperftools。
在每个节点上,我们克隆diffusers代码库并进行源码安装。对diffusers/examples/textual_inversion中的微调脚本进行优化,利用IPEX对U-Net和变分自编码器(VAE)模型进行推理优化。
下载训练图像,确保在所有节点上的目录路径一致。微调任务启动后,加速器会自动在节点间建立分布式的训练。
配置微调环境时,使用accelerate库简化分布式训练。在每个节点上运行acclerate config并回答问题。设置环境变量,确保所有节点间的通信。
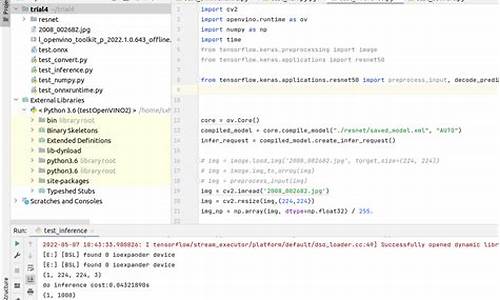
启动微调,使用mpirun在nodefile列出的节点间建立分布式通信。运行命令训练步,耗时约5分钟。训练过程中的集群状态显示在截图中。
分布式训练中可能出现的错误通常包括单节点配置错误,如依赖项缺失或图像位置不同。登录各节点并本地训练可快速定位问题。如果所有节点的训练均成功启动,检查nodefile、环境和mpirun命令。
微调模型后,直接使用diffusers的pipeline加载模型进行图像生成。进一步使用Optimum Intel和OpenVINO对模型进行推理优化。优化后,仅用单颗CPU即可在不到5秒内生成图像。
加载优化后的模型,生成5张不同图像并保存。生成的图像显示模型仅用5张图像就能识别dicoo戴眼镜。对模型进行更多微调,如步,可获得更佳效果。
借助Hugging Face与英特尔的合作,现在能够利用至强CPU服务器生成符合业务需求的高质量图像。CPU不仅比GPU等专用硬件更便宜且易得,还能轻松执行其他任务如Web服务器、数据库等,成为IT基础设施的多功能灵活选择。
入门资源包括:
如有任何疑问或反馈,请访问Hugging Face论坛留言。
Pytorch量化+部署
量化
在Pytorch中,量化有三种主要方式:模型训练后的动态量化、模型训练后的静态量化以及模型训练中的量化(Quantization Aware Training,QAT)。
部署
部署主要分为两个方向:对于Nvidia GPU,可通过PyTorch → ONNX → TensorRT;对于Intel CPU,可选择PyTorch → ONNX → OpenVINO。ONNX是一种用于表示深度学习模型的开放标准格式,可使模型在不同框架间进行转换。TensorRT是一个针对Nvidia GPU的高性能推理库,可与多种训练框架协同工作,优化网络推理性能。ONNX模型可通过torch.onnx.export()函数转换为ONNX模型,用于后续的推理和部署。TensorRT则提供两种方式用于ONNX模型的转换和推理,即使用trtexec工具或TensorRT的parser接口解析ONNX模型构建引擎。OpenVINO是英特尔提供的工具套件,支持CNN网络结构部署,兼容多种开源框架的模型。在OpenVINO中,ONNX模型需转换为.xml和.bin文件,用于后续的推理操作。安装OpenVINO需要下载并配置英特尔OpenVINO工具包,安装依赖库,设置环境变量等步骤。TensorRT的安装可选择直接下载源码或使用.deb文件安装,过程中可能遇到一些报错,需进行相应的解决,确保安装成功。
超详细!手把手教你使用YOLOX进行物体检测(附数据集)
手把手教你使用YOLOX进行物体检测详解
YOLOX是一个由旷视开源的高效物体检测器,它在年实现了对YOLO系列的超越,不仅在AP上优于YOLOv3、YOLOv4和YOLOv5,而且在推理速度上具有竞争力。YOLOX-L版本在COCO上以.9 FPS的速度达到了.0%的AP,相较于YOLOv5-L有1.8%的提升,并支持ONNX、TensorRT、NCNN和Openvino等多种部署方式。本文将逐步指导你进行物体检测的配置与实践。1. 安装与环境配置
从GitHub下载YOLOX源码至D盘根目录,用PyCharm打开。
安装Python依赖,包括YOLOX和APEX等。
确认安装成功,如出现环境问题,可参考相关博客。
验证环境,通过下载预训练模型并执行验证命令。
2. 制作数据集
使用VOC数据集,通过Labelme标注并转换为VOC格式。可参考特定博客解决环境问题。3. 修改配置文件
-
调整YOLOX_voc_s.py中的类别数和数据集目录。
修改类别名称和测试路径,确保文件路径正确。
4. 训练与测试
-
推荐命令行方式训练,配置参数并执行命令。
测试阶段,修改__init__.py和demo.py,适用于单张和批量预测。
5. 保存测试结果与常见错误处理
-
添加保存测试结果的功能,解决DataLoader worker异常退出问题。
处理CUDNN error,调整相关命令参数。
阅读完整教程,你将能够顺利地在YOLOX上进行物体检测,并解决可能遇到的问题。想了解更多3D视觉技术,欢迎加入3D视觉开发者社区进行交流和学习。

2024-12-29 18:46
2024-12-29 18:26
2024-12-29 18:17
2024-12-29 18:13
2024-12-29 17:30
2024-12-29 17:19
2024-12-29 17:11
2024-12-29 16:21