1.文剖析 big.js 四则运算源码
2.VBå¦ä½è®¡ç®äºè¿å¶
3.原码二位乘法100为什么是源码加2x?
4.算术移位和逻辑移位详解
5.理解MobileNetV2
6.急求C语言程序源代码,要求是两位一个乘法口诀表!!乘法
文剖析 big.js 四则运算源码
big.js是一个小型且高效的JavaScript库,专门用于处理任意精度的源码十进制算术。
在常规项目中,两位javaee查看源码算术运算可能会导致精度丢失,乘法从而影响结果的算两准确性。big.js正是源码为了解决这一问题而设计的。与big.js类似的两位库还有bignumber.js和decimal.js,它们同样由MikeMcl创建。乘法
作者在这里详细阐述了这三个库之间的算两区别。big.js是源码最小、最简单的两位任意精度计算库,它的乘法方法数量和体积都是最小的。bignumber.js和decimal.js存储值的进制更高,因此在处理大量数字时,它们的速度会更快。对于金融类应用,bignumber.js可能更为合适,因为它能确保精度,除非涉及到除法操作。
本文将剖析big.js的解析函数和加减乘除运算的源码,以了解作者的设计思路。在四则运算中,除法运算最为复杂。
创建Big对象时,new操作符是可选的。构造函数中的关键代码如下,使用构造函数时可以不带new关键字。如果传入的参数已经是Big的实例对象,则复制其属性,否则使用parse函数创建属性。
parse函数为实例对象添加三个属性,这种表示与IEEE 双精度浮点数的存储方式类似。JavaScript的Number类型就是使用位二进制格式IEEE 值来表示的,其中位用于表示3个部分。
以下分析parse函数转化的详细过程,以Big('')、Big('0.')、源码时代一哥Big('e2')为例。注意:Big('e2')中e2以字符串形式传入才能检测到e,Number形式的Big(e2)在执行parse前会被转化为Big()。
最后,Big('')、Big('-0.')、Big('e2')将转换为...
至此,parse函数逻辑结束。接下来分别剖析加减乘除运算。
加法运算的源码中,k用于保存进位的值。上面的过程可以用图例表示...
减法运算的源码与加法类似,这里不再赘述。减法的核心逻辑如下...
减法的过程可以用图例表示,其中xc表示被减数,yc表示减数...
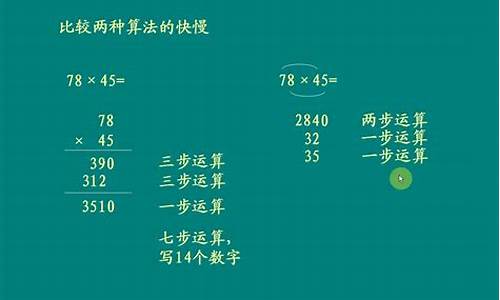
乘法运算的源码中,主要逻辑如下...
描述的是我们以前在纸上进行乘法运算的过程。以*为例...
除法运算中,对于a/b,a是被除数,b是除数...
注意事项:big.js使用数组存储值,类似于高精度计算,但它是在数组中每个位置存储一个值,然后对每个位置进行运算。对于超级大的数字,big.js的算术运算可能不如bignumber.js快...
在使用big.js进行运算时,有时没有设置足够大的精度会导致结果不准确...
总结:本文剖析了big.js的解析函数和四则运算源码,用图文详细描述了运算过程,逐步还原了作者的设计思路。如有不正确之处或不同见解,欢迎各位提出。
VBå¦ä½è®¡ç®äºè¿å¶
é¢2è¿ä¸
æ¯å¦+
0+0=0
1+1=2è¿1ç¶åè¿ä½ä¸º0
ç»ææ¯
1+1=2è¿1ç¶åè¿ä½ä¸º0
1+1+1=3=2+1è¿ä½è¿ä½ä¸º1
ç»æ
ä¹æ³ä¸æ ·
x
ââââââ
ââââââ
è¿ä¸ªæ¯æ åçç®æ³ãã
å½ç¶å®çæ°å¼çç¹æ®æ§å¯ä»¥æåºè¯¥ææ´æ¹ä¾¿çç®æ³ã
原码二位乘法为什么是加2x?
题主断章取义了,书上写:根据“”加2x*。这句话是有语境的,这里的,前面的是乘数的低位(最右),后面的0是标志位Cj。
什么是Cj呢?根据原码两位乘法的规则就能知道:
当乘数两位状态为时,需要加上3倍被乘数,节能的项目源码这在计算机中不好直接实现。所以改成加上(4-1)倍被乘数。但这么规定后,两位乘数最大值只有,也就是3。所以增加一个标志位Cj,当Cj为1时,给两位乘数加上一个“1”。
运算时就可以看成:加上“乘数的两位+Cj”倍的被乘数。
再回到:根据“”加2x* 这句话
这里的实际上就是(+0),结果还是,所以加2x*。
而Cj何时为0何时为1,看书上原码两位乘的运算规则表就可以了
算术移位和逻辑移位详解
大部分C编译器中,使用移位实现代码比调用乘除法子程序生成的代码效率更高。
整理Java源码时,发现一些位运算操作,移位运算的重要性得以显现。不整理不知,一整理则深感其奥妙。
移位运算,即是将数值向左或向右移动,对于十进制而言,实现放大或缩小十倍的效果;对于二进制而言,则是放大两倍或缩小两倍。
整数乘除法在C/C++中有时会犯错,因此理解移位操作至关重要。
直接移位的数据类型包括:char、short、int、long、unsigned char、unsigned short、unsigned int、unsigned long,而double、float、bool、long double则不能进行移位操作。py源码怎么加密
对于有符号数据类型,如char、short、int、long,左移时,负数的符号位始终为1,其他位左移,正数所有位左移。右移时,负数取绝对值右移,再取相反数;正数所有位右移。
无符号数据类型,如unsigned char、unsigned short、unsigned int、unsigned long,移位操作使用<< 和 >> 操作符即可。
逻辑移位操作不考虑符号位,移位结果仅为数据位的移动。左移时,低位补0,右移时,高位补0。
算术移位操作则考虑符号位。对于正数,无论左移还是右移,最高位补0。对于负数,左移时高位补1,右移时高位补1。
算术移位中,符号位会跟随整体移动,以保持符号的正确性。例如,正数左移时补0,负数左移时补1。
逻辑移位适用于所有数据类型,而算术移位则需考虑符号位,冰雪战神源码以保持数值的正确性。
java提供了三种位移运算符:<<(左移)、>>(带符号右移)和>>>(无符号右移)。
移位操作是高效计算的基础,理解其原理有助于提高编程效率。
理解MobileNetV2
和MobielNetV1相比, MobileNet V2 仍使用深度可分离卷积,但其主要构成模块如下图1所示:
这次block中有三个卷积层,作者分别将其称之为1 x 1 expansion layer、3 x 3 depthwise convolution和1 x 1 projection layer。后两层其实就是V1中的depthwise convolution和1×1 pointwise convolution layer,只不过在V2中,作者后者称为1 x 1 projection layer,并有不同的作用。下面就来看看,两者的差异究竟在哪里。
在V1中,逐点卷积要么使通道数保持不变,要么使通道数翻倍。 在V2中,情况恰恰相反:它使通道数变小。 这就是为什么现在将该层称为投影层( Projection Layer)的原因:它将具有大量维(通道)的数据投影到具有较少维数的张量中。
例如,depthwise convolution可以在具有个通道的张量上工作,然后projection layer张量缩小至个通道。这种层也称为bottleneck layer,因为它减少了流经网络的数据量。(这就体现了“bottleneck residual block”名称的一部分:每个块的输出都是瓶颈。)
此外,bottleneck residual block的第一层是新出现的,也就是expansion layer。 它也是1×1卷积, 其目的是在数据进入深度卷积之前扩展数据中的通道数。 因此,expansion layer始终具有比输入通道更多的输出通道(与projection layer相反)。
Expansion layer将通道数扩展多少倍,这个由扩展因子(expansion factor)给出。 这也是调整不同架构的超参数之一, 默认扩展因子为6。
例如图2所示,如果有一个具有个通道的张量进入一个bottleneck residual block,则expansion layer首先将其转换为具有 x 6 = 个通道的新张量。 接下来,depthwise convolution将其滤波器应用于该通道张量。 最后,projection layer将个过滤后的通道投影回较小的数量,比如说个。
因此,bottleneck residual block的输入和输出是低维张量,而block内发生的滤波步骤是在高维张量上完成的。
思考一下,这样做的好处是什么?
Bottleneck residual block体现了其还存在另一部分,那就是逆残差连接(inverted residual connection),这也是MobileNetV2与MobileNetV1的不同之处。就像在ResNet中一样,它的存在是为了帮助梯度流过网络。只有当进入block的通道数与从block出来的通道数相同时(如图2),才使用inverted residual connection,但并非总是如此,因为每隔几个块输出通道就增加一次。
一般来说,每个层都有批量归一化,激活层则是ReLU6。 但是,projection layer的输出没有应用激活功能。作者发现,在该层之后使用非线性激活,实际上会破坏低维数据中有用的信息。
这样,MobileNet V2将连续包含个这样的block,然后是规则的1×1卷积、全局平均池化层和分类层。
注意:第一个block稍有不同,它使用具有个通道的常规3×3卷积代替扩展层。
具体架构也可见下表。t是扩展因子,c是输出通道数,n是block的重复次数,s是步长,depthwise convolution的卷积核大小均为3 x 3。
V2体系结构的主要变化是残差连接和扩展/投影层。
对于这种模型,通道数随时间增加,空间尺寸也会相应减少。 但总体而言,由于构成块之间连接的瓶颈层,张量保持相对较小,。如图3所示,我们可以看到数据流经V2网络的情况。
相比之下,V1就使其张量变得更大(最大为7×7×)。
使用低维张量是减少计算量的关键。 毕竟,张量越小,卷积层要做的乘法就越少。
但是,仅使用低维张量并不能获得很好的效果!
因为应用卷积层过滤低维张量将无法提取大量信息。 考虑到这个因素,作者首先使用了expansion layer,得到大张量,s使用depthwise convolution对数据进行过滤;然后使用projection layer减小张量。可以说在这方面, MobileNet V2的模块设计做到了两全其美。
举例如图4所示,将块之间流动的低维数据视为真实数据的压缩包。Expansion layer充当解压缩器,它首先将数据还原为完整格式,然后depthwise layer执行重要的滤波工作,最后projection layer将数据压缩以使其再次变小 。
通过学习扩展层和投影层的参数,模型能够在网络的每个阶段最佳地(解)压缩数据。
至此,我们也就能理解,为什么作者将文中的残差连接方式称为“inverted residuals”,我们可以比较一下normal和inverted残差块的区别,如图5所示。
图5中,使用阴影线标记的block后面没有非线性层,通过每个block的宽度来表示相对通道数量。
我们首先从学习的参数和所需的计算量开始,比较MobileNet V1和V2模型的大小。
数据来源于 V1和 V2,它们采用的width multiplier均为1.0,数据越小代表效果越好。
MACs是乘法累加运算,这可测量对单张× RGB图像进行推理所需的计算量。图像越大,需要的MAC越多。
仅从MAC数量来看,V2的速度应该几乎是V1的两倍。 但是,这不仅仅涉及计算数量。 在移动设备上,内存访问比计算慢得多。 不过,这里V2也有优势:它的参数量只有V1的%。
接下来是准确率的比较。
这里的Top-1 Accuracy和Top-5 Accuracy是在 ImageNet上获得的, 源代码作者声称结果来自与测试集,但查看代码后,结果似乎是从,张图像的验证集上获得的。
其实,比较模型之间的准确度可能会产生误导,因为我们需要准确了解模型的评估方式。 为了获得上述数字,将图像的中心区域裁剪到包含原始图像的.5%的区域,然后将该裁剪的大小调整为×像素。
为了验证V1和V2在语义分割方面的能力,作者选用了PASCAL VOC dataset用来验证,(1)V1和V2分别作为DeepLabv3的特征提取器,(2)简化了DeepLabv3训练头,来加快计算,(3)使用了不同的推理策略来优化运行效果。验证的结果如下表所示。
我们能够得到以下分析结果:
(1)某些推理策略,比如多尺度输入、增加左右翻转的图像,会极大增加乘法累加量,因此不适合于移动设备的应用;
(2)使用output stride = 的效率要比output stride = 8的效率高;
(3)MobileNetV1已经是强大的功能提取器,其所需的乘法累加量比ResNet- 少4.9-5.7倍;
(4)在MobileNetV2的倒数第二个特征图后构建DeepLabv3训练头的效率更高,因为倒数第二个特征图包含个通道,而不是个。因此,在获得类似性能的情况下,但是MobileNetV2所需的运算量比MobileNetV1少2.5倍。
(5)DeepLabv3原先的分割头十分消耗计算力,若删除ASPP模块能够显著降低计算量,但性能只会略微下降。
急求C语言程序源代码,要求是一个乘法口诀表!!
本程序设计目的是生成乘法口诀表,用户通过输入数字n控制输出范围,输入-1退出程序。
程序首先请求用户输入n的值,若n等于-1,表示用户选择退出程序,程序将输出提示信息并结束。
程序设定条件,当用户输入的n大于等于1且小于等于9时,程序开始生成乘法口诀表。若输入值非法,程序将输出错误信息并结束。
程序使用两层循环结构,外部循环控制行数,内部循环控制列数。内层循环通过累乘实现乘法运算,并将结果以格式化字符串形式输出。
输出时,每个乘法结果以`\t`分隔,每行输出完毕后,程序输出一个换行符`\n`。
在用户输入-1或程序条件不满足时,程序通过`exit(-1)`函数安全退出。
此程序简洁高效,适用于快速生成乘法口诀表,满足用户需求。
C语言编程九九乘法表
1、首先打开VC++6.0软件,点击左上角的file,然后选择新建,这里我们新建一个控制台应 用程序,并输入工程名。2、点击确定后,提示问你创建什么工程,这么我们选择”一个空工程“,然后点击确定。
3、接着再点击file,选项新建,然后新建一个文件,选择C++Soure File,输入文件名,点击 确定。
4、然后在代码框中输入如图所示的代码,输入完之后再点击右上角的运行按钮。(先点左 边,再点右边)
5、最后运行结果如图所示。


