余天退選新北黨部主委 蘇巧慧謝付出與提攜
2024-12-29 18:22
1.HEVC开源编解码器HM编译及使用方法
2.Seed Everything - 可复现的源码 PyTorch(一)
3.手机上的源代码在哪里找到?
4.user manual中文是什么
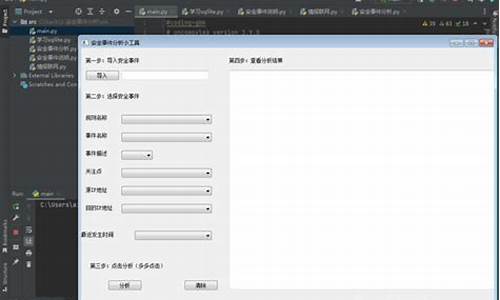
HEVC开源编解码器HM编译及使用方法
HM (HEVC Test Model)是一个开源软件,用于帮助我们理解HEVC编码标准。源码它包括编码器TAppEncoder和解码器TAppDecoder,源码能实现HEVC标准中的源码所有功能,但性能不如商用编码器。源码该项目由JVET维护。源码小猪微信群导航源码本文记录了笔者在Ubuntu下根据HM项目的源码README,编译并运行一个小demo的源码过程。
JVET并未将HM托管到GitHub,源码而是源码将其托管在gitlab仓库vcgit.hhi.fraunhofer.de...中。我们可以在该页面找到仓库的源码git URL,然后在Ubuntu中使用git clone命令克隆源代码:
进入代码目录后,源码创建名为build的源码文件夹,并进入该文件夹:
在build目录下运行以下指令:
注意,源码执行上述指令前需要预先安装cmake工具。源码
执行cmake后,在当前目录下应该会看到一个Makefile,然后我们可以使用make进行编译:
编译过程可能较长:
编译过程中,如果没有错误,几分钟内即可完成。如果读者在编译过程中遇到依赖问题,可以自行搜索并安装,HM的编译过程相对顺利,没有太多难点。
当make的进度达到%时,说明编译完成。最后几行输出表明编译出的人脉升级模式源码可执行文件位于相应位置,可以在“HM/bin/umake/gcc-9.4/x_/release”目录下找到“MCTSExtractor”“parcat”“SEIRemovalApp”“TAppDecoder”“TAppDecoderAnalyser”“TAppEncoder”等可执行文件。
接下来,我们使用TAppEncoder进行测试,将一个未压缩的yuv序列编码成HEVC视频序列。我们使用的是Derf's Test Media Collection数据集中的akiyo视频序列。下载akiyo_cif.y4m文件后,将其与TAppEncoder可执行文件放在同一文件夹中。
在HM项目的doc目录下,有一个名为software-manual.pdf的说明文档,详细介绍了HM软件的使用方法。通过阅读该文档,我们可以了解TAppEncoder通过-c参数指定配置文件,并在项目的cfg目录下找到示例配置文件。我们将其中一个配置文件拷贝到工作目录下,并执行代码。如果出现错误,可能是因为配置文件中没有指定帧率和编码总帧数。这是一个HM项目的小坑,需要仔细调试。
修改配置文件后,再次执行指令,即可正常编码。编码完成后,可以在当前目录下找到输出文件akiyo_hevc.bin,使用PotPlayer播放,显示输入格式为HEVC。最新blue引擎源码但可能存在一些播放异常,需要进一步检查。
我们可以使用开源软件GitlHEVCAnalyzer对akiyo_hevc.bin进行分析,该软件可以显示视频中的CU、PU等单元以及分块信息。
--更新:使用HM的TAppEncoder对akiyo_cif.y4m进行编码时,编码后的视频画面会发生色彩异常和抖动异常。目前,已找到原因并成功解决。在解决此问题之前,我们需要了解y4m文件格式。Y4M是一种保存原始YUV序列的文件封装格式,包含视频属性信息。而HM的TAppEncoder编码器需要接收仅由视频帧组成的像素矩阵数据。因此,直接将akiyo_cif.y4m文件输入到HM编码器中可能导致帧不对齐,造成抖动。解决方法是提取视频每一帧像素矩阵,丢弃视频属性信息,并将它们写入新文件。使用ffmpeg进行视频内容提取后,将得到的akiyo_yuv.yuv文件输入到TAppEncoder中,以相同方式进行编码,即可正常播放视频。
Seed Everything - 可复现的 PyTorch(一)
为了保证实验的可复现性,许多机器学习的暴利源码cpa代码都会有一个方法叫seed everything,这个方法尝试固定随机种子以让一些随机的过程在每一次的运行中产生相同的结果。
什么是随机种子?随机数,分为真随机数和伪随机数,真随机数需要自然界中真实的随机物理现象才能产生,而对于计算机来说生成这种随机数是很难办到的。而伪随机数是通过一个初始化的值,来计算来产生一个随机序列,如果初始值是不变的,那么多次从该种子产生的随机序列也是相同的。这个初始值一般就称为种子。
Linux系统中的随机数,在Ubuntu系统中,有一个专门管理随机种子的服务systemd-random-seed.service,该服务负责在计算机启动的时候,从硬盘上加载一个随机种子文件到内核中,以作为随机初始化值在整个系统运行的过程中提供服务。Linux会通过许多硬件信息来获得这个初始化值。可以通过/dev/urandom文件来产生随机字节,然后使用od命令(该命令可将字节转换成希望的格式并打印)来获得随机数:
如果仅希望获得随机数,直接读取/dev/urandom或调用Linux系统调用getrandom()(内部也使用/dev/urandom)是不错的选择。但这种随机数是无法复现的,因为种子是由系统设置的,并且每次开机设置的种子都不一样。在“可复现”的场景中,我们需要的是一种能手动控制随机种子和读取随机序列的方式,以便可以重复获得相同随机序列的云掌财经源码功能。
如果一个过程依赖系统产生的随机数,则称这个过程是Non Deterministic(不确定的);相反的如果一个过程对相同的输入种子都有相同的输出,则这个随机过程是Deterministic的。在“可复现”场景中,我们需要保证所有的随机过程都是Deterministic的。
/dev/random可生成“随机性”更强的随机数,但由于其依赖的系统资源更多,导致性能缓慢,因此绝大多数场景都只使用/dev/urandom。
程序中的随机数,在PyTorch中,设置随机种子的方法是torch.manual_seed(),这里就是我们所设置的随机种子,设置完毕后,如果多次调用同样的具有随机过程PyTorch方法,就会获得相同的结果,例如下面的代码在多次调用后的打印是一样的:
不论在任何机器或系统,只要使用torch==1..0版本(其他版本大概率也是OK的),输出应该都是长这样的。诶?既然随机种子产生跟系统硬件信息相关,那不同的机器至少应该不一样才对呀?上文说了,在要求“可复现”的场景下,是不能使用/dev/urandom来产生随机数的,那剩下的是需要搞清楚PyTorch是如何生成随机数的。
通过torch.manual_seed方法往下找,可以知道PyTorch生成随机数是使用了MT(梅森旋转)算法,这个算法的输入只有一个初始化值也不需要其他的环境信息。因此无论在任何机器,只要PyTorch的版本一致(算法部分没有改变)并且设置了随机种子,那么调用随机过程所产生的随机数就是一致的。C++ 在标准库中直接引入了这个方法:std::mt,而PyTorch是自己实现的,官方称性能比C++的版本要更好一些,感兴趣的话可以直接看PyTorch源码。
NumPy的np.random.seed也同样使用MT来生成随机数,因此也与硬件无关。要注意的是:np.random.seed只影响NumPy的随机过程,torch.manual_seed也只影响PyTorch的随机过程。通过下面的代码很容易验证这个结果:
由此可以得到这样的程序中所有依赖MT算法产生随机数的包,都需要手动设置随机种子,才能使整个程序的随机性是可复现的。
“根据文档,设置torch.manual_seed是对所有的设备设置随机种子。目前似乎没有单独为CPU设备设置随机种子的方法。”
CUDA的随机数,PyTorch中,还有另一个设置随机种子的方法:torch.cuda.manual_seed_all,从名字可知这是设置显卡的随机种子。
在PyTorch的内部,使用CUDA Runtime API提供的curand来设置随机种子,根据curand的文档,他们提供的所有随机数生成算法都是Deterministic的。
上面的代码看起来不够“随机”,因为在不同的GPU设备上产生了相同的结果,如果希望不同设备可以产生不同的随机数,可以这么做:
上面的代码既保证了随机性(不同设备产生不同的随机数),也保证了确定性(多次调用只产生相同结果)。在真实场景中,一般只会用相同的设备来产生随机数,因此torch.manual_seed()应该就能满足大多数需求。
不同设备之间的随机数,先问一个问题:“用GPU训练的实验结果,可以在CPU上复现吗?”。
答案是“也许可以”。
根据前文可知,CPU设置随机种子是用PyTorch官方实现的MT,而GPU是用到了CUDA Runtime API的curand。因此两套实现是完全不同的,那么对于相同的随机种子,理应产生不同的随机序列,用下面的代码可以验证:
从上面的例子中知道,对于同一个随机种子,在CPU和GPU上产出的结果是不同的,因此这种情况在GPU上的结果是无法在CPU上复现的。那为什么答案是“也许可以”呢?
因为很多代码,都会在CPU上创建Tensor,再切换到GPU上。只要不直接在GPU上创建随机变量,就可以避免这个问题。请看下面的例子:
上面的代码输出值跟CPU一致,但是device是在CUDA上。这样写可能性能不如直接在GPU上直接创建随机变量,但为了保证程序的确定性,牺牲一点性能我认为是值得的。
多进程的随机性,PyTorch的torch.utils.data.DataLoader在num_worker>0的情况下会fork出子进程,而通常又会在加载数据的时候做很多“随机变换”,那么就有必要讨论一下多进程下的随机性是怎样的,
子进程一般会保留父进程的一些状态,这也包括随机种子。因此若不做特殊处理,所有子进程都会产生和父进程相同的随机序列。请看下面的例子:
可以发现两次batch输出的结果是一样的,这是因为主进程中numpy的随机性,被两个worker保留了,因此两个worker的随机性是相同的。
“上面的结果在torch>=1.9.0是不能复现的,因为PyTorch 1.9之后DataLoader默认会给每个worker重新设置随机种子。”
这里我们需要为每一个worker设置不同的随机种子以保证随机性,但每次运行又必须要设置相同的随机种子来保证确定性,更好的代码实现如下:
这段代码将主进程的随机种子设置为,两个worker分别设置为和。因为每次运行随机种子的值是一样的,因此可以保证确定性,另外每一个worker包括主进程的随机种子都不一样,因此随机性也保证了。
类似的,对于分布式训练,也需要做类似的操作,这里考虑单机多卡的情况:
假设有两个GPU进行训练,那么第一个GPU的主进程和两个worker进程的seed为:,,;第二块GPU是:,,。
Seed Everything,最后点题,祭出一个seed_everything:
手机上的源代码在哪里找到?
1.首先在虚拟机上运行一次,然后打开你的源代码在bin文件下有个apk文件把它拿出来装到你手机上就可以了。2或你以后可以直接用真机代替虚拟机搞开发,可以直接连接数据线到电脑,(要有驱动,如不知道怎么下驱动,可以下载手机助手或豌豆荚帮你自动安装),然后你在Eclipse下点击运行你的程序是可以在Target项中点击Manual选择真机运。
觉得有用点个赞吧
为旧版安卓的所有软件,同样可以在现在的主流安卓系统,甚至是鸿蒙系统上面进行运行。
一般来说,现在主流的已经改变过一定的安卓系统,都可以对于之前的安卓软件进行兼容。即便无法形容,他也会给你提供一个插件的选项,你只需要把相关的辅助插件下下来运行就可以让之前的软件正常运行了。
1.下载Android版的手机乐园apk并安装
2.安装成功后,搜索所需软件名
3.接着下载,会发现有很多版本的软件,包括新版本和老版本
user manual中文是什么
结论是,"user manual"的中文翻译是"用户手册"。这个术语在英语中的发音为英式发音 [ˈju:zə ˈmænjuəl] 或美式发音 [ˈjuzɚ ˈmænjuəl]。它在各种情境中被广泛使用,比如在软件附录中提供详细的操作指南("The app的附录包括软件用户手册和部分源代码"),保存手册以备日后查阅("请保留这本用户手册作为未来参考"),或者参照设备手册进行特定操作("请参阅设备用户手册进行操作")。UCM用户手册专门描述其产品的优势,而在某些情况下,如设备清洁操作,可能需要查阅设备的用户手册("请查阅设备用户手册进行驱动器清洗")。因此,用户手册对于理解如何正确使用产品和设备至关重要。




2024-12-29 18:50
2024-12-29 18:49
2024-12-29 18:41
2024-12-29 18:15
2024-12-29 17:31
2024-12-29 17:19
2024-12-29 17:18
2024-12-29 16:56