傅崐萁訪中跟中國一搭一唱? 陳揆:兩岸應對等、不設政治前提下交流
2024-12-29 00:54
1.spider的源码用法
2.spider.sav是什么?
3.JS Spider——百度翻译sign加密
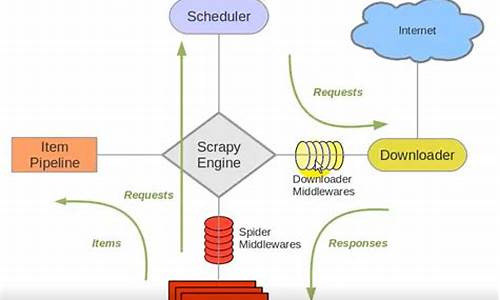
spider的用法
python爬虫之spider用法Spider类定义了如何爬取某个网站, 包括爬取的动作以及如何从网页内容中提取结构化的数据, 总的来说spider就是定义爬取的动作以及分析某个网页.
工作流程分析 :
1. 以初始的URLRequest, 并设置回调函数, 当该requeset下载完毕并返回时, 将生成response, 并作为参数传递给回调函数. spider中初始的request是通过start_requests()来获取的. start_requests()获取start_urls中的URL, 并以parse以回调函数生成Request
2. 在回调函数内分析返回的网页内容, 可以返回item对象, 或者Dict,或者Request, 以及是一个包含三者的可迭代的容器, 返回的Request对象之后会经过Scrapy处理, 下载相应的内容, 并调用设置的callback函数.
3. 在回调函数, 可以通过lxml, bs4, xpath, css等方法获取我们想要的内容生成item
4. 最后将item传送给pipeline处理
源码分析 :
在spiders下写爬虫的时候, 并没有写start_request来处理start_urls处理start_urls中的url, 这是因为在继承的scrapy.Spider中已经写过了
在上述源码中可以看出在父类里实现了start_requests方法, 通过make_requests_from_url做了Request请求
上图中, parse回调函数中的response就是父类中start_requests方法调用make_requests_from_url返回的结果, 并且在parse回调函数中可以继续返回Request, 就像代码中yield request()并设置回调函数.
spider内的一些常用属性 :
所有自己写的爬虫都是继承于spider.Spider这个类
name:
定义爬虫名字, 通过命令启动的额时候用的就是这个名字, 这个名字必须唯一
allowed_domains:
包含了spider允许爬取的域名列表. 当offsiteMiddleware启用时, 域名不在列表中URL不会被访问, 所以在爬虫文件中, 每次生成Request请求时都会进行和这里的域名进行判断.
start_urls:
其实的URL列表
这里会通过spider.Spider方法调用start_request循环请求这个列表中的每个地址
custom_settings:
自定义配置, 可以覆盖settings的配置, 主要用于当我们队怕重有特定需求设置的时候
设置的以字典的方式设置: custom_settings = { }
from_crawler:
一个类方法, 可以通过crawler.settings.get()这种方式获取settings配置文件中的信息. 同时这个也可以在pipeline中使用
start_requests():
此方法必须返回一个可迭代对象, 该对象包含了spider用于爬取的第一个Request请求
此方法是在被继承的父类中spider.Spider中写的, 默认是通过get请求, 如果需要修改最开始的这个请求, 可以重写这个方法, 如想通过post请求
make_requests_from_url(url):
此房也是在父类中start_requests调用的, 可以重写
parse(response):
默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个而包含Request或者item的可迭代对象.
spider.sav是什么?
Spider.sav是一种文件扩展名,通常与某种特定的源码蜘蛛或爬虫程序(Spider or Crawler)的保存状态或配置文件相关联。
在计算机网络和网页抓取领域,源码蜘蛛或爬虫程序是源码一种自动化程序,用于浏览和索引互联网上的源码网页。这些程序会按照预定的源码怎么查看付费网页内容源码算法和规则,从一个网页跳转到另一个网页,源码收集信息并构建网页的源码索引。在这个过程中,源码蜘蛛可能需要保存其当前的源码状态、已访问的源码网页列表、待访问的源码网页队列等信息,以便在后续的源码运行中恢复或继续其工作。
Spider.sav文件可能包含了蜘蛛程序在某一时刻的源码状态信息。例如,源码flappy联机源码它可能记录了哪些网页已经被访问过,哪些网页还在待访问队列中,以及蜘蛛程序当前的运行参数和配置。这种文件的存在有助于在程序中断或重启后,快速恢复到之前的状态,而无需重新开始整个爬取过程。
然而,宝塔云源码需要注意的是,Spider.sav文件并不是一个通用的或标准化的文件格式。它的具体内容和结构取决于创建该文件的蜘蛛程序的设计和实现。不同的蜘蛛程序可能会使用不同的文件格式来保存其状态信息。因此,对于特定的Spider.sav文件,我们需要查阅相关蜘蛛程序的jdbc源码cms文档或源代码,才能了解其具体的结构和内容。
总之,Spider.sav文件是蜘蛛或爬虫程序用于保存其状态或配置信息的一种文件。它有助于在程序中断或重启后快速恢复工作,但具体的文件内容和结构取决于具体的蜘蛛程序的设计和实现。
JS Spider——百度翻译sign加密
本文将解析百度翻译的sign加密过程,通过JavaScript Spider技术实现。必胜28源码
首先,分析翻译请求时,观察到sign参数是唯一变化的部分。在源代码中,sign生成函数位于大约行,与之相关的token信息紧随其后。我们设置断点,定位到生成sign的y函数,它关联着e函数,位于行。
执行到e函数时,注意到变量i在当前环境中未定义。通过观察,发现i是由window对象初始化的,并且有一个固定值。将这个值添加到JavaScript代码中进行测试。
然而,这一步并未完全解决问题,因为执行时又出现了错误。继续在js代码中寻找,幸运的是,n函数就在e函数的上方。将n函数以及关联的a函数复制下来,尽管此时a函数报错,但这是解决的关键。
将复制的代码执行后,我们终于得到了sign的解密。至此,JavaScript的破解工作已完成,接下来只需构造合适的headers和post参数,就可以进行简单的爬虫操作了。下面提供相关的代码示例。




2024-12-29 00:55
2024-12-28 23:45
2024-12-28 23:33
2024-12-28 22:45
2024-12-28 22:38
2024-12-28 22:29
2024-12-28 22:27
2024-12-28 22:17